工作
提出了spartz,一个紧凑的、模块化的32bit向量处理单元(vector processing unit),指令集采用RVV1.0的嵌入式子集zve32x。
作者通过将 Spatz 集成到 MemPool(一种大规模多核共享 L1 集群)中来分析其性能。基于 Spatz 的 MemPool 系统在运行 256 × 256 32 位整数矩阵乘法时可实现高达 285 GOPS的性能,比基于 Snitch 的等效 MemPool 系统高出 70%。在能效方面,基于 Spatz 的 MemPool 系统在运行相同内核时可实现高达 266 GOPS/W,是基于 Snitch 的 MemPool 系统的两倍多,后者的能效达到 128 GOPS/W。这些结果表明,精益矢量处理器作为具有紧密耦合 L1 内存的大规模集群的高性能和节能 PE 的可行性。
Arm 的 M-Profile 向量扩展 (MVE) 和 RISC-V 向量扩展 (RVV) 的 Zve* 子集都针对用于边缘数据并行处理的小型向量机,而不是高性能计算。
Spartz
架构
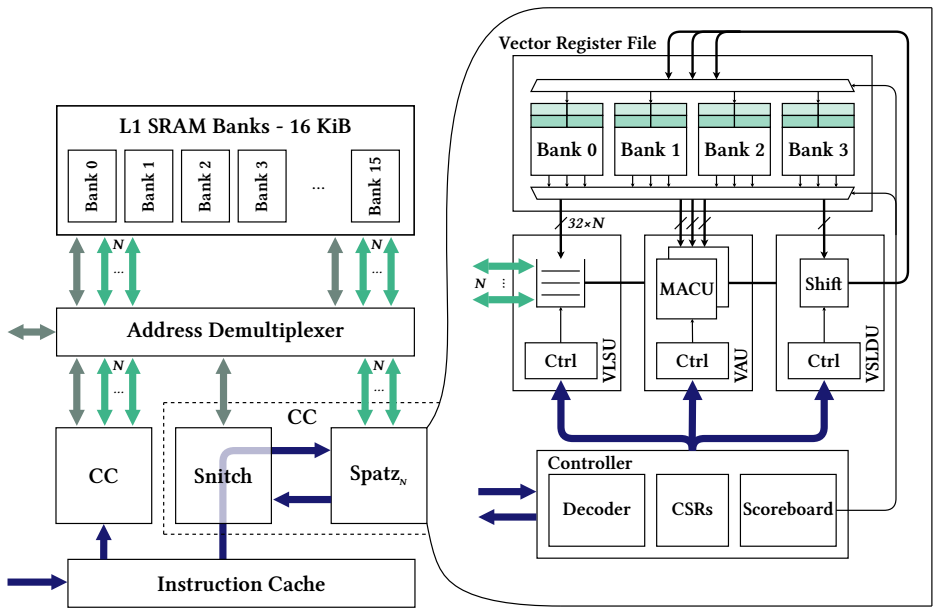
图1是SpartzN的微架构,右侧是一个具有N个乘加单元 (Multiply-Accumulate Units , MACUs)的Spartz。左侧展示了Spartz如何在 MemPool 块内集成。Spatz 有一个基于锁存器的 VRF,分为四个组,具有三个读取端口和一个写入端口 (3R1W)。 VRF 为 Spatz 的功能单元提供数据。Spatz 的控制器负责跟踪in-flight中的矢量指令和与标量核心的接口,在我们的例子中是 Snitch,它负责执行标量指令并将矢量指令转发给 Spatz。Snitch 和 Spatz 形成一个 (a Core Complex, CC)
Spatz 与处理器无关。它通过通用的 CORE-V X-Interface 加速器接口 [OpenHW Corp. 2022. OpenHW Group eXtension Interface. OpenHW Corp. https://docs.openhwgroup.org/projects/openhw-group-core-v-xif Revision a3bcdd76]. 与标量核心通信。 因此,Spatz 可以与任何兼容 X-Interface 的核心交互。我们选择使用 Snitch 是因为它占用空间极小,适用于大多数计算发生在向量机中的向量执行范式。不幸的是,由于接口规范仍处于起步阶段,它不能很好地适应向量机的内存带宽要求。考虑到加速器可能使用宽度比标量核心更宽的内存接口访问内存,作者扩展了这个X-Interface。当Spartz的vector LSU执行一次内存访问时,作者通过暂停标量核心的LSU来保证Spartz和标量核心内存访问的顺序,反之亦然。
控制器
标量核心只对矢量指令进行预译码,并派遣矢量指令和任何标量操作数到spartz,Spatz的controller解码矢量指令,跟踪它们的执行,并与Snitch确认它们的完成。控制器还管理RVV ISA的控制寄存器和状态寄存器(CSRs)。例如,vlen CSR定义了所有向量指令的向量长度。另一个重要的CSR是vtype,它控制向量元素的宽度以及是否将物理向量寄存器分组为更长的逻辑向量寄存器,这种分组称为Length Multiplier(LMUL),它允许逻辑向量长度最多达到机器向量长度的8倍,但代价是可用的逻辑向量寄存器更少。最后,控制器协调functional units中矢量指令的执行。记分牌记录每个向量指令有多少个元素被提交到VRF中。矢量指令之间的冒险通过operand backpressure处理。Spatz通过在每个元素的基础上计算冒险来支持chaining。
Vector Register File
VRF是任何vector machine的核心。在Spatz中,我们决定使用3R1Wbank的多bank多port VRF。每个bank都使用基于锁存的标准单元存储器(SCM)来实现。Spatz的VRF也是集中式的,服务于所有Spatz的function unit。VRF port匹配vmacc指令的吞吐量需求,该指令读取三个操作数以产生一个结果。每个组是VLEN/4位宽,并且32个VLEN位宽的向量寄存器中的每个占用四个VRF bank中的一行。每个VRF port的宽度是32N bits 宽(其中N是Spatz的MACUs的数目)。
Functional Units
Spatz有三个functional unit,分别是Load/Store Unit (VLSU),
tArithmetic Unit (VAU),以及Vector Slide Unit (VSLDU)。
- VLSU:LSU处理Spatz的内存接口,支持unit-strided和constant-strided内存访问。VLSU支持参数数量的32位宽内存接口。默认情况下,内存接口的数目与设计中macu的数目匹配。这意味着每个内存带宽比的峰值操作为0.5 OP/B。 Spatz独立且狭窄的内存访问接口允许它复用标量核使用的32bit宽的L1 SPM互连。由于VLSU不需要将请求合并到大容量的内存传输中,独立的接口还允许快速的恒步执行和潜在的分散收集执行。但是,由于各个内存响应请求之间没有排序保证,因此在内存接口和VRF之间有一个Reorder Buffer (ROB)。ROB确保将内存响应按照32𝑁-bit-wide字的顺序写入VRF,从而简化了记分牌中的链接机制
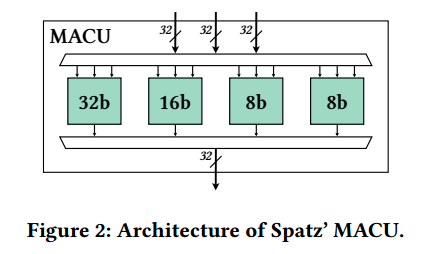
- VAU:矢量算术单元。VAU是Spatz的主要功能单元,托管主管N个MACUS。MACU支持8位、16位和32位元素。无论元件宽度如何,每个MACU每个周期都有32位的吞吐量。在一个MACU内,执行以打包的simd方式进行。图2显示了其中一个macu的架构。为了节省区域,MACU有四个数据路径,一个32位宽,一个16位宽,两个8位宽。窄操作重用宽数据路径。每个数据路径实现一个乘法器、加法器、比较器和移位器。MACU数据路径支持的最复杂的操作是vmacc,这是一个乘法累加操作,每个结果需要三个源操作数。
*
- VSU:VSLDU执行向量置换指令。这类指令的例子包括矢量向上/向下滑动和矢量移动。LSU在两个32N-bit宽的私有寄存器banks上操作。在两个寄存器banks中,全互联的存在允许所有的置换操作。常见的操作,例如slides,每周期生成一个32N位的结果,这与其它functional unit的峰值吞吐量匹配。寄存器bank同样扮演类似于VLSU中的ROB的角色,不仅仅要对这些寄存器做double-buffering,同时还要确保unit提交给VRF的宽度为32N-bit,这通过增加记分牌的粒度简化了记分牌中的链接计算。
实验与评估
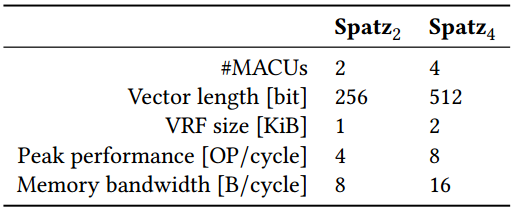
作者将分析具有关键数据并行kernal的基于spatz的PE的性能。我们考虑两个不同大小的Spatz配置,Spatz2和Spatz4。它们的设计参数如表1所示。所有Spatz配置都是为每内存带宽比为0.5 OP/B的峰值操作而设计的。
作者使用关键的计算受限的信号处理kernal来对单个Spatz单元进行基准测试,这些kernal对存储在本地低延迟L1内存中的矩阵进行操作。
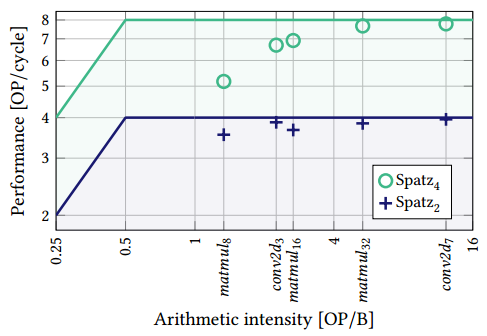
对于所考虑的基准测试,Spatz2达到了近乎理想的MACU利用率。matmul基准的峰值性能为3.84 OP/cycle (96.0%), conv2d基准的峰值性能为3.95 OP/cycle(98.8%)。大型内核在Spatz4上也能达到非常高的性能。它在matmul内核上的峰值性能为7.67 OP/cycle(95.8%),在conv2d内核上的峰值性能为7.78 OP/cycle(97.2%)。‘
PPA
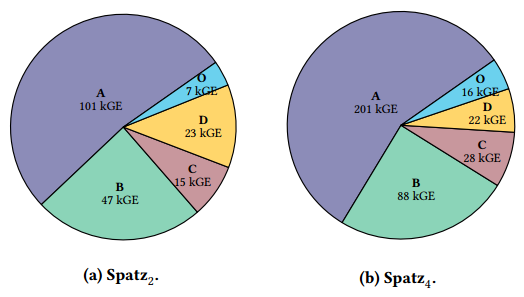
Synopsys的Fusion Compiler 2022.03,使用GlobalFoundries的22FDX FD-SOI技术综合出了基于Spatzand snitch的小型共享l1集群。我们的目标是在最坏情况下(SS/0.72 V/125°C) 500 MHz。下图显示了Spatz2和Spatz4的CC合成后的区域分布,A=VRF,B=VAU,C=VLSU,D=
snitch,O=others。
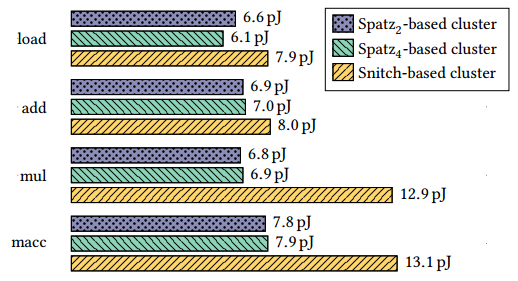
运行通用指令时,基于Spatz2、基于Spatz4和基于snitch集群的每次基本操作的能耗。所有集群实例化4个MACU。